
HBCUs are different. There’s universal inside jokes about the outdated processes of financial aid departments taking forever during registration only to end up with blaring errors, hiccups, and long waits. Whether we’re talking about institutions’ slowness to adapt to more progressive technologies for completing registration, for instance, requiring paper versions of digital assets, or mistakes like presenting campus housing hurdles delaying move-in dates, it seems that these challenges exist across multiple historical black colleges and universities. In the HBCU alumni circles, we all agree that these obstacles are a part of the core experience and teach us first-hand about patience, efficiency, and persistence.
This idea got me thinking about my major and how I didn’t feel quite prepared for the world after graduating with my Bachelor of Arts in Mass Communication in 2008. My classes at that time centered around using Web 1.0 (the read only web) methodologies like QuarkExpress for newspaper layouts, various journalistic writing styles, and other key philosophies that I’d argue were outdated as major course focuses by the time I graduated. The transition to Web 2.0 (the participative social web) was in full swing and along with it came real-time comments, social networks, and algorithms. I graduated in a time where newspapers were becoming phased out as news took to social media, but my college coursework hadn’t factored in these changes to the landscape.
Higher education meets lifecycle marketing with proper data maintenance
Enter today. I’m wondering if the curriculum has kept up, but more importantly to me as a marketer, how are HBCUs keeping up on the data front. Southern University as an institution has been around since 1880, so naturally there should be a treasure trove of data from matriculating students, prospects, and alumni. In the most basic of expectations, there should be a relevant database from the past 15 years (I graduated in 2008) as this would represent alumni still ripe for post-graduate programs, Southern University Law School, doctoral programs, and more importantly this range would include alumni with current high school graduate aged children who could be marketed to as new college enrollees.
You see, I’d expect a major university to have a Lifecycle Marketing program in place that segments and markets 1:1 to their marketable audience. For instance, if an individual happens to load the Southern University homepage, I’d expect some Form to trigger in an attempt to capture that person’s information. We might even tie that form to a Subscribe to Newsletter, Stay Connected, or some other enticing call-to-action. The goal is to discover each stranger’s intent and then to place them in Lifecycle marketing funnels, nurture journeys, or various other communications that ultimately result in a conversion through enrollment or other performance indicator. As a University, there’s at the very least 4 years to acquire over 500 different points of data for each prospect, student, or alumni that we can use to further market for profitability later down the funnel. We should be building a student or lead profile for each person who completes our form or indicates explicit interest in our Courses, Pricing, or other trigger content.
I’m 37, and I just had my first set of twins, who are also my first children, however many of my college colleagues had children far earlier than I did. So, my crude math says that there is a contingent of alumni who are 38 and had kids by at least 20, so they’d have 18 year olds who can be marketed to as long as we have the data. This brings me to my point about keeping up with the times. The data. We should be able to segment students and people who visit our web properties into specific buckets based on all the collected data points if we’re allowing data into the system properly.
One university as a case study
As a small case study, I decided to log back into Southern University’s Apply portal to do some digging. My case study would entail logging into SUBR online to start an application for enrollment. This login would be my first since 2008 and will tell me a lot about SUBR’s data governance. Simply possessing data doesn’t equate to much without actually leveraging it. I’d wager that leveraging this data properly can be the deciding factor for enrollment numbers. Luckily, Southern has been doing something right in the realm of out-of-state enrollees as they had 891 total out of state students in 2017, while in fall of 2023 the school boasted that the number rose to 2,196 – an increase of 146% says a report by the Public Affairs Research Council.
Its not my intent to bully Southern University A&M or any other Historical Black College or University, but rather to bring light to an often forgotten area of responsibility we should be investing into – the data. Its our responsibility as stewards of website channels and student relationships to apply proper guardianship towards data collection. As a marketer, I’m a firm believer that appropriate marketing programs are just as valuable and essential to data guardianship as safeguarding data and not leveraging it. In fact, in the age of algorithms, I’d rather be marketed relevant content than irrelevant, but I’m aware that that’s subjective positioning as its not a black and white topic. I do want HBCUs to start paying closer attention to how they are collecting, curating, and leveraging data. If I had to stand on a reason for using them as an example, its that. In comparison, universities like Louisiana State University, Alabama State University, and Cornell, don’t have the same issues – they have their own unique data issues that I might explore in a later blog post.
96,000+ untapped student profiles
I’ve worked for over a dozen universities who are all utilizing unique methods for acquiring student prospective information online. One of the most prevalent and easy to accomplish would be that of a Journey. There should be a clean student, prospect, or lead profile that can be sorted and segmented into a list that can be included in one of several journeys. For instance, prospective students from Louisiana could be tagged in Salesforce, synced into Marketing Cloud, and fall within a data extension for InStateUndergradProspects2025. We could even take it a step further and segment down into InStateUndergrad_CommsProspects2025 to specify a degree program. We can only safely and efficiently use lists/data extensions for journeys if the journey criteria/ data is clean, up to date, and accurate. A great journey options would even entail repeating an information confirmation email yearly to keep track of former students as they travel throughout life. In this way, we can smartly implement 1:1 strategies that reinvest, onboard, and speak to people where they are in their journey.
Since 2008, Southern University has matriculated or enrolled around 96,000 individuals. Where is their data? What dorms did they live in? What can we tell about their campus experience from their data? Well, we can only speak to that if we have the data in question. I consider it an egregious misstep to allow that data to go unused, untapped, and out dated. Those 96,000 records easily equated to over 30,000 potential alumni children who could have been marketed to for enrollment. That’s over $48,000 in potential revenue per email campaign and over 250 potential additional new student registrations per semester.
Just some quick student math
I’d log my experience, much like I’m doing here, to determine what HBCUs are actually doing under the hood as it relates to housing the data of over 96,000 individuals give or take. First, let’s breakdown how I got the 96k number:
To estimate the total number of students who likely matriculated through Southern University Baton Rouge since 2008, we can use a simple estimation method based on average annual enrollment figures and the number of years since 2008.
Let’s assume a conservative estimate of the annual enrollment at Southern University Baton Rouge has been around 6,000 students since 2008. This is a rough approximation and may not reflect actual enrollment figures for each year, but it provides a baseline for estimation.
Now, let’s calculate the total number of students who likely matriculated through Southern University Baton Rouge since 2008:
- Total years since 2008 = 2024 (current year) – 2008 (starting year) = 16 years
Average annual enrollment = 6,000 students - Total estimated students = Average annual enrollment × Total years since 2008
- Total estimated students = 6,000 students/year × 16 years = 96,000 students
So, using this estimation method, it’s likely that approximately 96,000 students have matriculated through Southern University Baton Rouge since 2008. Keep in mind that this is a rough estimate and the actual number may vary.
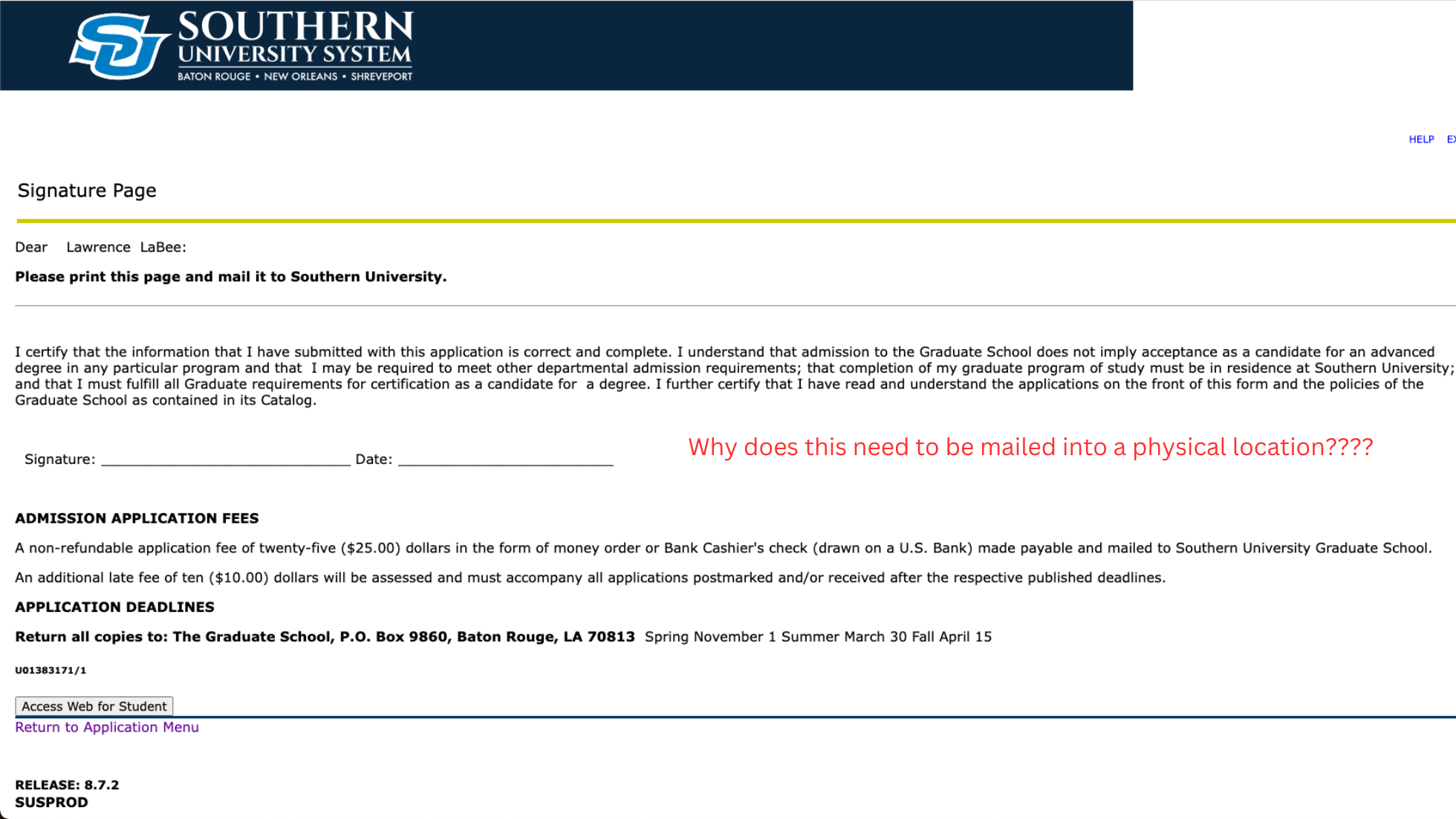
SUBR's Apply Now intake form can use some TLC
Consider the importance of intake forms, which serve as a crucial data source and support various firm processes. However, managing the sheer volume of information captured, sometimes up to 500 data points per form, can be daunting. While data is essential for firm operations, it’s crucial to assess whether each piece of information collected is truly necessary and accurate. In the case of Southern’s initial Apply Now form, it represents a broken data source in need of some TLC.
Educating client-facing and support teams about the required data and its purpose is invaluable. The primary intake form for Southern’s Apply Now is in desperate need of review and rebuild. Each data point requires input and review, potentially leading to time-consuming back-and-forth communications in case of inaccuracies. Emphasizing a “right first-time” approach where all stakeholders take accountability can minimize such inefficiencies. As the form lives now, its creating student profiles with bad county and country fields, while also just maintaining old data with no means of updating it. We can’t effectively and safely include records in journeys with this configuration as we can’t trust the data. I haven’t logged in in years but the system displayed my old data quick and effortlessly (this isn’t a good thing lol).
1. Old and outdated data
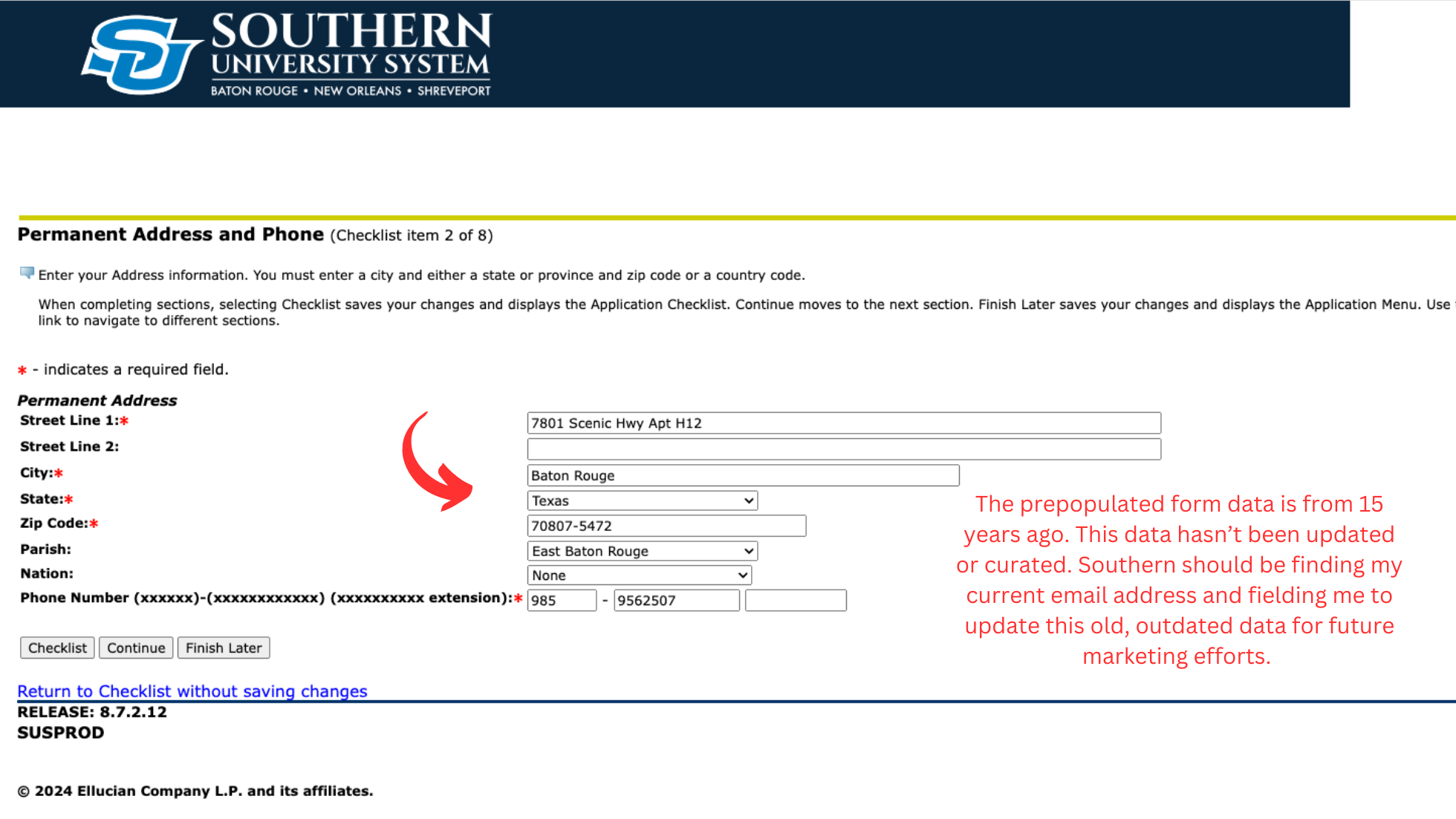
I think its commendable that Southern University still has my outdated data on file, as its a testament to at least 15 years of data housing. The fact that data must live somewhere and storage costs should also be in the back of our minds as we unravel the online application experience and its subsequent leveraging of our data through marketing. As a stakeholder, I’d want to be making money off of my housed data or at least moving needles to justify housing old data. We could be leveraging data for marketing to prospective students, post graduates who might re-enroll, and even to support other business initiatives.
In a perfect world, SUBR would be sending me annual emails leading to landing pages prompting me to update all my personal information. That info should then update my student/alumni record and be used to segment me into various buckets, for instance Alumni NOT registered in Alumni Federation or Alumni Residing in Texas, or even a repository that checks for my status in the enrollment system to cross verify my alumni status. This would also allow us to send mail like promotions for football games, vouchers for alumni shopping, etc.
2. Make Picklists tight for better data hygiene
“Your data should tell a story. You want to be sure that story is accurate, and that you’re able to report it up correctly and with confidence.”
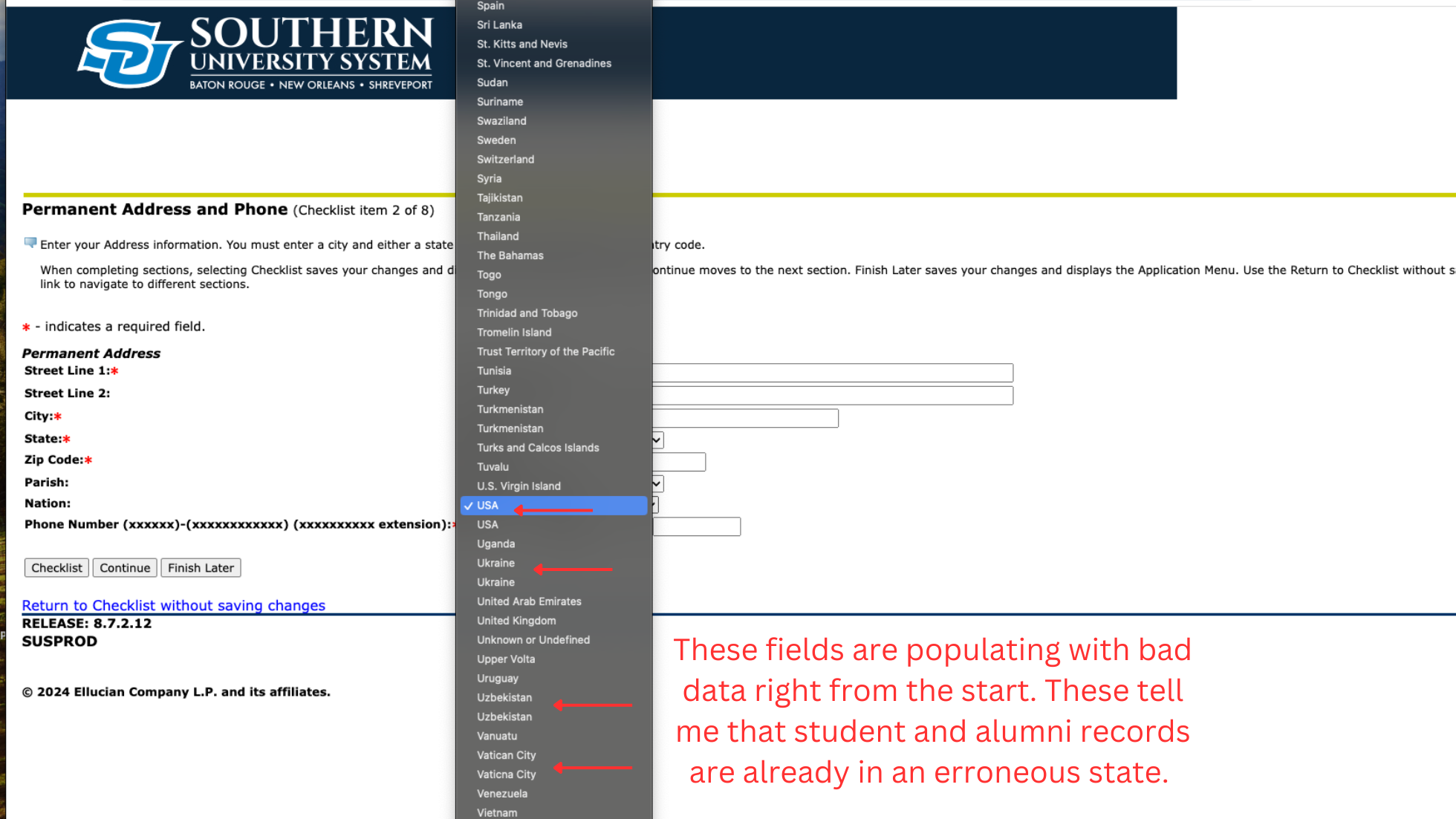
This form uses Picklists to populate options for Country, but as we can see in the example, there are duplicates and misspells in some of the options. It’s tough to ascertain as to what extent this misconfiguration is affecting data as we don’t know what data types each selection is tied to. At best, selecting either of the duplicate options would register as a Country input. At worst, both options are misconfigured in their data type.
In the spirit of troubleshooting, we’d also want to explore where these duplicated and misspelled Picklist options are coming into the system from. Are they configured in a universal settings for the field or is the system somehow allowing users to update the Picklist options with their responses. I can see the second scenario if this was set up during a time where we expected the user to know more countries than we have list options, but I can’t see this as a viable setup in modern times. Today, we should be allowing the options we want and including any straightforward options, but not allowing field options to be updated based on submission values – not that we’ve solidified this as the case per se, but it does look that way.
3. Tidy up dependent Picklist fields
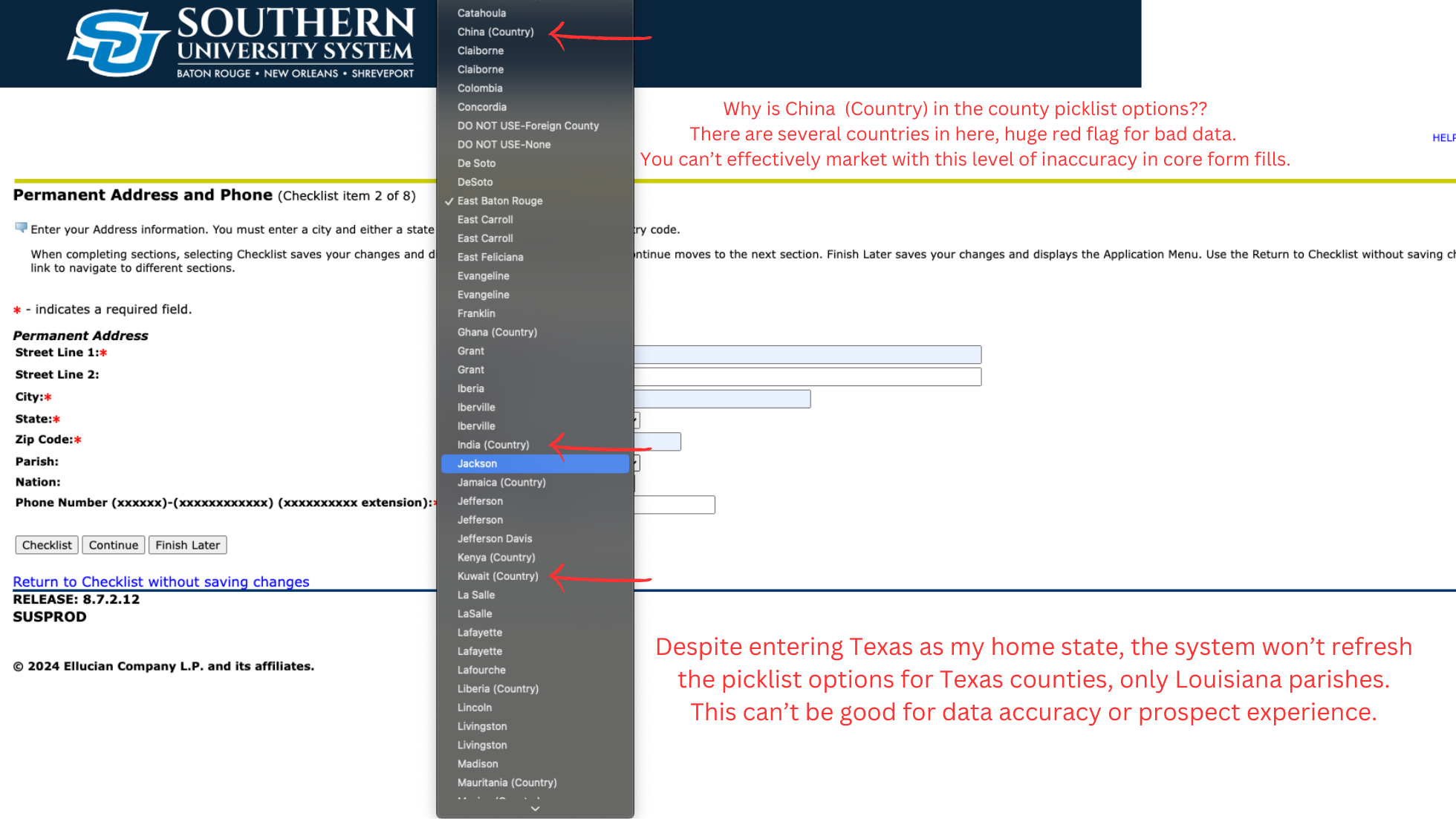
Another error in the intake form lies in the Parish Picklist item. I think this form field was intended to refer dependent on the State field so it shows counties or parishes native to the specified State selection. Instead, what we get here is a Picklist that populates Louisiana Parishes with the odd additions of specific Countries as selections. This should have been caught in QA, UAT, or level of software delivery. The first Picklist scenario was definitely a user configuration error, but this seems to be more of system generated error. It seems as though the list just isn’t updating with the field dependency. Either way, this hurts the student onboarding experience and is a bad look for the university before even stepping foot on campus. In this particular instance, the error could really make the brand look uncooked or unfinished. It doesn’t inspire confidence in the institution when critical items like this are mismanaged on the frontend no less.
On the data front, this Picklist inconsistency is directly impacting data health and data integrity. Now, there are a number of profiles that using duplicated and misconfigured field values, misplaced Countries, and jumbled info in the County/Parish field. Again, we can’t properly set up clean nurture journeys with this level of erroneous data.
4. Phase out traditional for digital first experiences
HBCUs are acquiring data but not doing anything with it. We could easily fix these issues by redesigning and reproaching the way we develop forms. By missing out on opportunities for good data, we forfeit the gains, profits, and key performance indicators possible with lifecycle marketing programs. HBCUs often seem like last to the table in several essential technological innovations among higher education institutions. We can turn the tides on several worthy fronts by taking data serious and leveraging it towards actionable insights. Finally, I’d love to see HBCUs like my alma mater adopt progressive data governance strategies and grow to their maximum potential across digital.
Summary
In conclusion, its my current short-term mission to audit and advocate for historically black colleges and universities to catch-up to best practices in data management. Organizations are losing out on countless 1:1 marketing engagements through a lack of actionable data. In addition, students would love to receive relevant information to help pad out their knowledge of their university, college, or activity programs – what better way than to use CRM platforms and available data.




